In my recent series on Scoped Vector Search, we looked at the query patterns that make vector search a first-class citizen in MySQL. While the logic for those searches is now established, the infrastructure supporting them requires constant attention as the MySQL ecosystem moves toward its new release model.
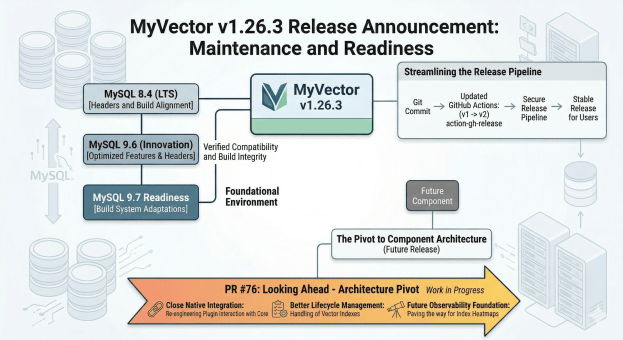
Today, I’m announcing MyVector v1.26.3. This is a foundational release focused on environment compatibility and CI/CD robustness.
What’s in v1.26.3?
This release ensures that MyVector remains stable and buildable across the shifting landscape of MySQL Innovation and LTS releases.
- MySQL 8.4 & 9.6 Compatibility: We’ve updated the component sources and build logic to align with the headers and requirements for MySQL 8.4 (LTS) and the 9.6 Innovation release.
- Ready for 9.7: The build system has been adapted to handle the upcoming 9.7 release, ensuring that users can transition to the next Innovation branch without delay.
- Modernized Release Workflow: We’ve bumped our GitHub Actions (softprops/action-gh-release) from v1 to v2. While invisible to the user, this ensures our release pipeline remains secure and compatible with the latest GitHub runner environments.
Think of v1.26.3 as the “maintenance and readiness” layer that ensures the high-performance HNSW search you rely on continues to compile and run perfectly on the newest versions of MySQL.
Looking Ahead: The Architecture Pivot (PR #76)
While v1.26.3 keeps us current, the real excitement is happening in the lab.
There is a fundamental architecture change currently in development under Component migration (8.4–9.6) and release workflow update.
Unlike the compatibility fixes in today’s release, PR #76 is a structural overhaul. We are re-engineering how the plugin interacts with the MySQL core. This shift is designed to move MyVector closer to a full Component Architecture, which will eventually offer better lifecycle management and even deeper integration with MySQL’s internal services.
This is a significant pivot in how MyVector is built, and it will set the stage for the next generation of vector performance and observability.
Summary
v1.26.3 is the stable, verified update you need for today’s MySQL 8.4/9.6 environments and tomorrow’s 9.7 upgrade. Meanwhile, work continues on the architectural evolution that will define the future of the project.
- Download the Release: v1.26.3 on GitHub
- Watch the Evolution: Component migration (8.4–9.6) and release workflow update

