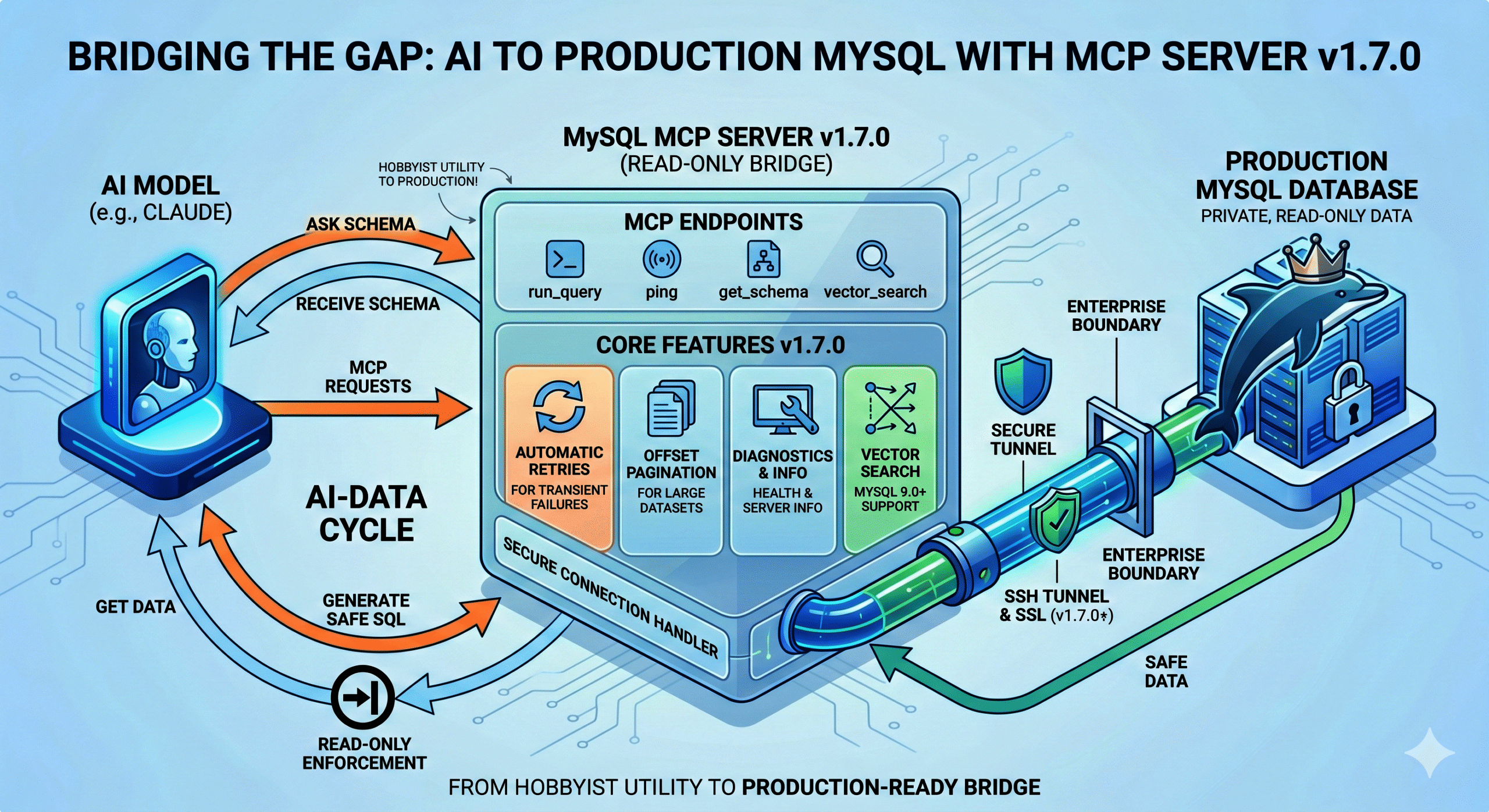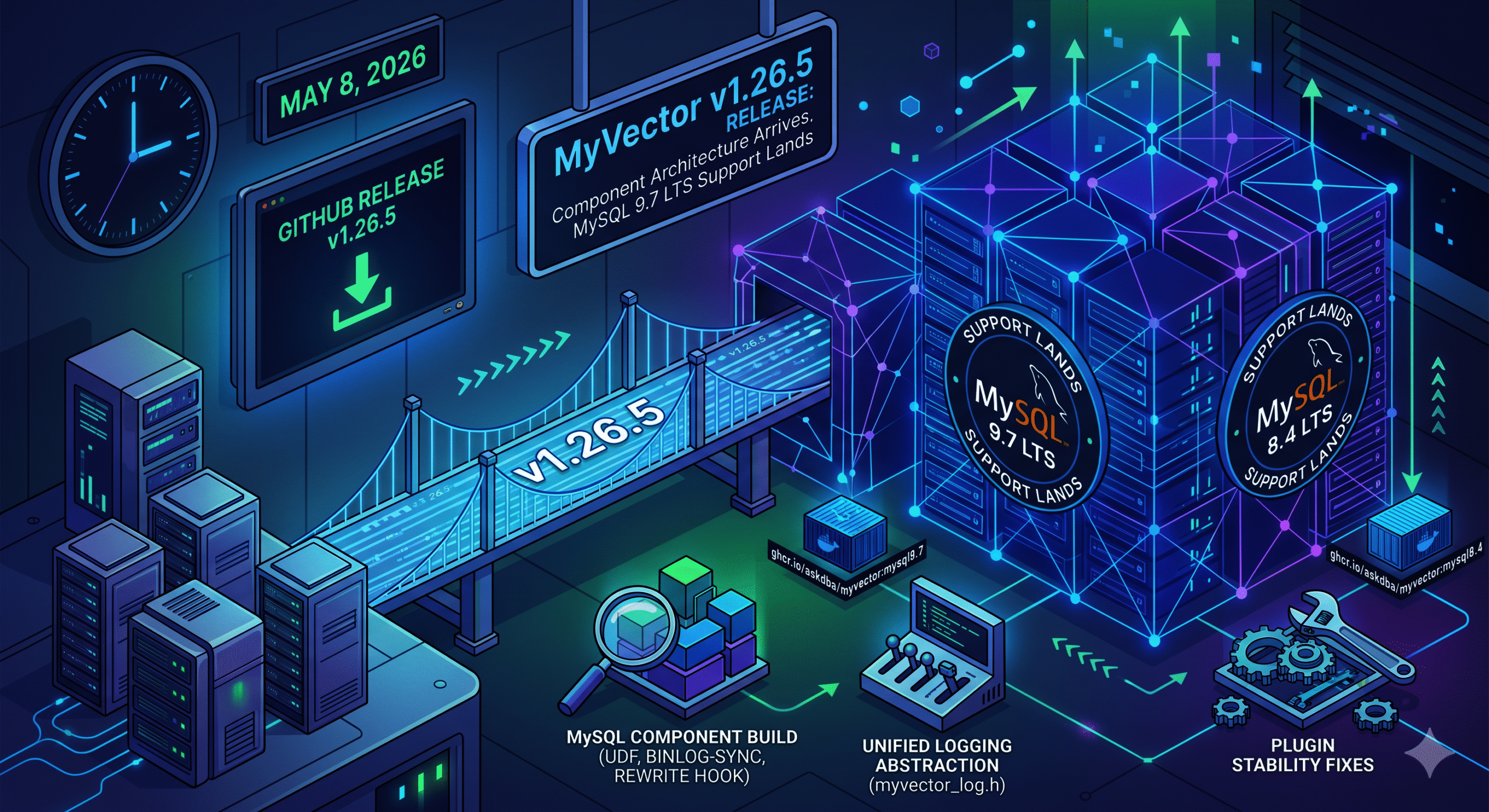
MySQL 9.7 LTS Support Lands Released May 8, 2026 · GitHub Release
v1.26.5 introduces a MySQL Component build for MySQL 8.4 LTS and 9.7 LTS, a unified logging abstraction, and a set of plugin stability fixes. The plugin path for MySQL 8.0, 8.4, and 9.0 is unchanged.
Why the Component architecture matters
MySQL has been deprecating the legacy plugin API in favor of the Component architecture since 8.0. Components install via INSTALL COMPONENT, integrate through typed service interfaces, and are better isolated from server internals — meaning fewer breakages across MySQL minor versions and a supported path forward as the plugin API winds down. For MyVector, this move isn’t optional in the long run: the component model is where MySQL’s extension ecosystem is heading, and building on it now means users on 8.4 LTS and 9.7 LTS get a stable, upgrade-resilient foundation rather than a deprecated one.
What’s New
MySQL Component build. MyVector can now be installed via INSTALL COMPONENT on MySQL 8.4 and 9.7. The component ships UDF registration, binlog-driven index synchronization, and a query rewrite service hook — all backed by the same core vector index engine as the plugin. A new myvector_log.h abstraction unifies logging across both build modes, replacing scattered #ifdef blocks.
MySQL 9.7 LTS. The 9.x CI, release, and Docker targets move from 9.6 to 9.7 LTS. A new Docker image tag ghcr.io/askdba/myvector:mysql9.7 is now available. If you’re on :mysql9.6, switch to :mysql9.7.
Plugin stability fixes. gmtime() and asctime() replaced with their thread-safe _r variants; concurrency fixes in plugin init/deinit; null-guard added to myvector_ann_set row function. Also: config file permission hardening, a binary_log namespace conflict fix on 8.4/9.7, and a Quick Start wget URL correction (issue #89).
How to Install
Component — pre-built binaries (Linux amd64) are attached to this release:
bash
tar -xzf myvector-component-mysql8.4.8-linux-amd64.tar.gz
cp libmyvector_component.so $(mysql_config --plugindir)/
mysql -u root -p -e "INSTALL COMPONENT 'file://libmyvector_component';"Also available: myvector-component-mysql9.7.0-linux-amd64.tar.gz and checksums.txt. To build from source, use scripts/build-component-8.4-docker.sh or scripts/build-component-9.7-docker.sh.
Plugin — Docker or build from source. Pre-built plugin .so files are not on the release page. Use Docker (multi-arch, amd64 + arm64):
bash
docker pull ghcr.io/askdba/myvector:mysql8.4 # or :mysql8.0, :mysql9.7Or build from source with scripts/build-release.sh (requires MySQL dev headers).
Upgrade Notes
- No schema or index migration required.
- Docker tag change:
:mysql9.6→:mysql9.7. - The component path is the forward path for MySQL 8.4+. The plugin remains supported for 8.0/8.4/9.0 through their EOL dates.
- Windows is not supported — use Linux container images.
See docs/BUILD_MODES.md and docs/COMPONENT_MIGRATION_PLAN.md for migration guidance. Bugs and feedback welcome on GitHub Issues.