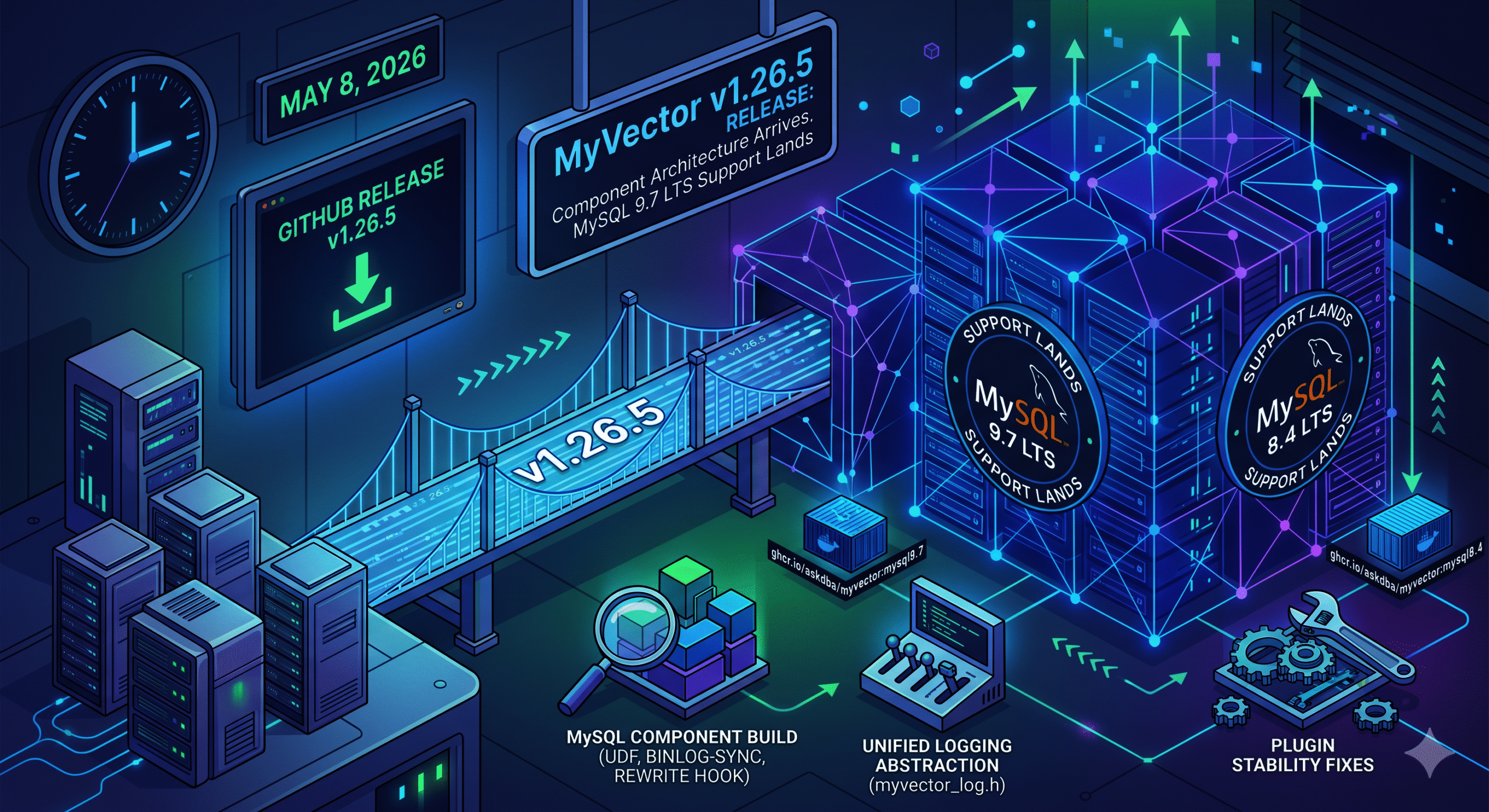
MySQL 9.7 LTS Support Lands Released May 8, 2026 · GitHub Release
v1.26.5 introduces a MySQL Component build for MySQL 8.4 LTS and 9.7 LTS, a unified logging abstraction, and a set of plugin stability fixes. The plugin path for MySQL 8.0, 8.4, and 9.0 is unchanged.
Why the Component architecture matters
MySQL has been deprecating the legacy plugin API in favor of the Component architecture since 8.0. Components install via INSTALL COMPONENT, integrate through typed service interfaces, and are better isolated from server internals — meaning fewer breakages across MySQL minor versions and a supported path forward as the plugin API winds down. For MyVector, this move isn’t optional in the long run: the component model is where MySQL’s extension ecosystem is heading, and building on it now means users on 8.4 LTS and 9.7 LTS get a stable, upgrade-resilient foundation rather than a deprecated one.
What’s New
MySQL Component build. MyVector can now be installed via INSTALL COMPONENT on MySQL 8.4 and 9.7. The component ships UDF registration, binlog-driven index synchronization, and a query rewrite service hook — all backed by the same core vector index engine as the plugin. A new myvector_log.h abstraction unifies logging across both build modes, replacing scattered #ifdef blocks.
MySQL 9.7 LTS. The 9.x CI, release, and Docker targets move from 9.6 to 9.7 LTS. A new Docker image tag ghcr.io/askdba/myvector:mysql9.7 is now available. If you’re on :mysql9.6, switch to :mysql9.7.
Plugin stability fixes.gmtime() and asctime() replaced with their thread-safe _r variants; concurrency fixes in plugin init/deinit; null-guard added to myvector_ann_set row function. Also: config file permission hardening, a binary_log namespace conflict fix on 8.4/9.7, and a Quick Start wget URL correction (issue #89).
How to Install
Component — pre-built binaries (Linux amd64) are attached to this release:
bash
tar -xzf myvector-component-mysql8.4.8-linux-amd64.tar.gz
cp libmyvector_component.so $(mysql_config --plugindir)/
mysql -u root -p -e "INSTALL COMPONENT 'file://libmyvector_component';"
Also available: myvector-component-mysql9.7.0-linux-amd64.tar.gz and checksums.txt. To build from source, use scripts/build-component-8.4-docker.sh or scripts/build-component-9.7-docker.sh.
Plugin — Docker or build from source. Pre-built plugin .so files are not on the release page. Use Docker (multi-arch, amd64 + arm64):
bash
docker pull ghcr.io/askdba/myvector:mysql8.4 # or :mysql8.0, :mysql9.7
Or build from source with scripts/build-release.sh (requires MySQL dev headers).
Upgrade Notes
No schema or index migration required.
Docker tag change: :mysql9.6 → :mysql9.7.
The component path is the forward path for MySQL 8.4+. The plugin remains supported for 8.0/8.4/9.0 through their EOL dates.
Windows is not supported — use Linux container images.
MySQL 9.7 came out on April 21 and I’ve been going through the release notes so you don’t have to. The short version: Oracle has made severalpreviously Enterprise-only features available in the Community Edition; the Hypergraph Optimizer is now free for everyone; and if you’re still on MySQL 8.0, it has reached End-of-Life. Like right now. We’ll get to that.
Let’s go through what matters most.
First: MySQL 8.0 has reached End-of-Life
MySQL 8.0.46 shipped alongside 9.7, and it is the last 8.0 release. As of April 2026, 8.0 is officially End-of-Life. No more security patches. No more bug fixes. Oracle’s release notes now encourage users to upgrade to MySQL 8.4 LTS or 9.7.
If you’re on 8.0 in production, you’ve got two paths. MySQL 8.4 LTS is the safest, most conservative upgrade with a well-trodden migration path from 8.0. MySQL 9.7 is if you want all the new stuff, including everything in this post. Either way, the clock has run out on 8.0. It is strongly recommended to plan your upgrade soon.
Some Enterprise features available in the Community Edition
This is the headline. Oracle has moved five components from Enterprise Edition into Community Edition with this release. For self-hosted MySQL users, this is genuinely good news.
Four of them are replication components that now ship in Community Edition.
Replication Applier Metrics gives you real visibility into how your replica is processing events. Lag monitoring, throughput, the works. This was always the kind of thing you had to implement separately or access the Enterprise Edition.
Group Replication Flow Control Statistics now provides visibility into why your GR cluster is throttling. If you’ve ever stared at a slow cluster and had no idea what was happening under the hood, this one’s for you.
Group Replication Resource Manager lets you control how resources get allocated so replication stops starving your app workloads.
Group Replication Primary Election gives better observability into failover behavior during primary elections, which is exactly when you most need to know what’s going on.
And then there’s the Telemetry component, which is big if you’re running MySQL in a cloud-native setup. Metrics and traces can now flow to Prometheus, OpenTelemetry, and whatever else your observability stack includes. This was Enterprise-only until today.
The Hypergraph Optimizer is in Community Edition now
This is the one that stands out as particularly impactful.
Quick background: MySQL’s traditional query optimizer uses a left-deep tree approach to figure out join order. Works fine for simple queries, but with complex multi-table joins it can miss a lot of better execution plans. The Hypergraph Optimizer takes a completely different approach. It models the whole query as a hypergraph and uses dynamic programming to search a much bigger space of possible plans.
If you’ve got complex reporting queries or anything with a lot of joins, it’s worth turning on and seeing what happens.
To try it:
SET optimizer_switch=’hypergraph_optimizer=on’;
You can set it at session scope (great for testing), globally, persistently across restarts, or hint it on a per-query basis. Start with session scope on your actual slow queries before you go global. The optimizer is solid, but you don’t want surprises in production.
JSON Duality Views are now fully supported in Community
Previously, in Community Edition, you could define JSON Duality Views, but couldn’t do INSERTs, UPDATEs, or DELETEs through them. That was an Enterprise thing. This capability is now available in Community Edition.Full DML is now in Community.
They also added auto-increment support for duality view inserts, which means you can stop manually wiring up primary keys:
The order_id gets generated automatically. Small change, but it removes a real friction point if you’ve been experimenting with duality views.
A few other things worth knowing
Password hashing got stronger.caching_sha2_password now supports PBKDF2 with SHA-512 storage format. Your existing clients don’t need to change anything since this is server-side only, but it makes stored hashes significantly harder to brute-force. Worth noting if you’re in a compliance-heavy environment like PCI-DSS or HIPAA.
Rolling upgrades just got easier. There’s a new variable called replica_allow_higher_version_source that lets a lower-version replica connect to a higher-version primary. Practically, this means you can upgrade your primary first, verify everything looks good, and then roll through your replicas at your own pace instead of taking the whole fleet down at once.
Container users, this one’s for you. MySQL now correctly reads cpuset cgroup limits to figure out how many CPUs are actually available to it. If you’d constrained MySQL to 4 CPUs in Kubernetes, it might have been sizing its thread pools against all 32 host CPUs anyway. That’s fixed.
OpenSSL got bumped to 3.5.5. Not exciting, but good hygiene.
What about Vector search?
A lot of people are asking about this, and the current status is that it is not yet generally available. Oracle is clearly building toward native vector search across the 9.x innovation releases, and you can see pieces of the foundation being put in place. But 9.7 isn’t the release where it lands as something you can use. It’s on the roadmap, it’s coming, the team is looking for feedback, and it is expected in future releases. As some of you know, I’m especially interested in vector features as a maintainer of the MyVector project. We’ve had a couple of calls with the engineering team to collaborate on this subject. This might be an area for community contributions. Please stay tuned.
So, should you upgrade?
Your situation
What to do
Still on MySQL 8.0
Upgrade. It’s EOL. Pick 8.4 LTS or 9.7.
On 8.4 LTS, happy where you are
Nothing urgent. Track 9.7 for the LTS landing.
Running Group Replication
Try the new components.
Complex JOIN-heavy queries
Benchmark the Hypergraph Optimizer.
Running MySQL in Kubernetes
The cgroup CPU fix alone might be worth it.
Excited about vector search
Not yet. Watch this space.
MySQL 9.7 is available at dev.mysql.com/downloads. If you end up benchmarking the Hypergraph Optimizer or trying the new replication components, share your results. The community learns from real-world numbers a lot more than from release notes. Drop them in the MySQL Community Forums or tag #MySQL97.
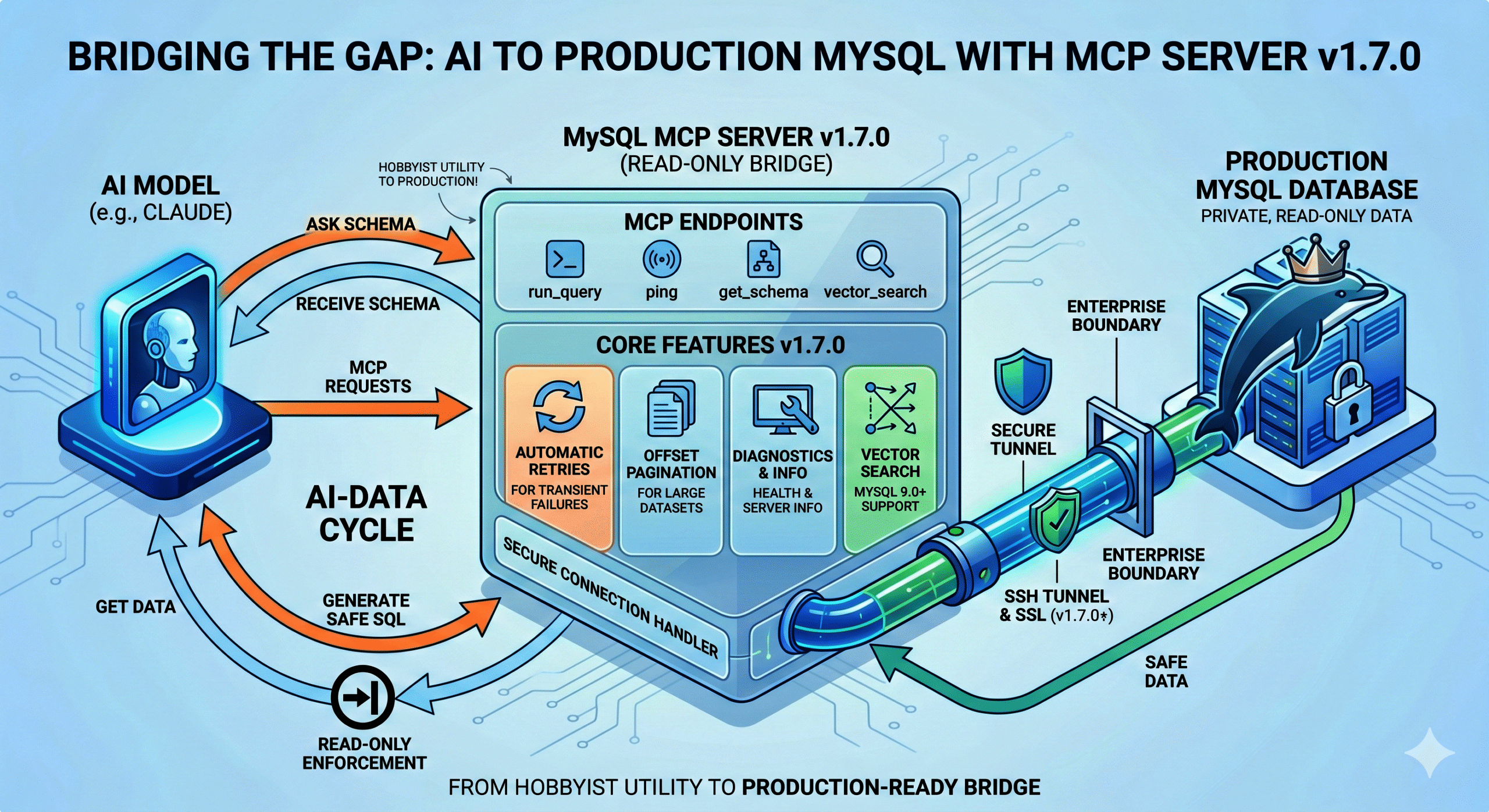
It took three release candidates and more CI tweaks than I’d like to admit, but v1.7.0 is finally tagged GA. Here’s what actually changed and why it matters.
The thing I kept getting asked about: add_connection
Almost every multi-database user hits the same wall: you configure your connections at startup, and that’s it. Want to point Claude at a different instance mid-session? Restart the server. Not great.
add_connection fixes that. Enable it with MYSQL_MCP_EXTENDED=1 and MYSQL_MCP_ENABLE_ADD_CONNECTION=1, and Claude can register a new named connection on the fly — DSN validation, duplicate-name rejection, and a hard block on the root MySQL user all happen before the connection is accepted. Once it’s in, use_connection it works as usual.
It’s intentionally opt-in behind two flags. Allowing an AI client to register arbitrary database connections at runtime warrants an explicit “yes, I want this” from the operator.
Finding stuff across a big schema: search_schema and schema_diff
Two tools I personally felt the absence of every time I was debugging a large schema.
search_schema does what it sounds like — pattern-match against table and column names across all accessible databases. Before this, you’d either write the query yourself or ask Claude to guess where a column lived. Now you just ask.
schema_diff is the one I’m more excited about. Point it at two databases, and it tells you what’s structurally different. Columns that exist in staging but not prod, type mismatches, missing indexes — all surface immediately. We’ve already caught more than a few “oh, that migration never ran” moments with it.
Pagination, retries, and the unglamorous stuff
run_query now supports an offset parameter for SELECT and UNION queries, returning has_more and next_offset in the response. Big result sets no longer mean hitting row caps and wondering what you missed.
Retries got a proper implementation too. Transient errors — bad pooled connections, deadlocks, lock wait timeouts — now trigger exponential backoff instead of just failing. After a driver.ErrBadConn the pool is re-pinged, which cuts recovery time noticeably after a MySQL restart.
Neither of these is flashy, but they’re the kind of thing that makes the tool feel solid rather than fragile.
Column masking
Set MYSQL_MCP_MASK_COLUMNS=email,password,ssn and those columns are redacted in every run_query response. Nothing leaves the server. No query rewrites, no application changes. It’s a small feature that a few teams have been asking for since before v1.6.
One breaking change worth knowing about: SSH host key verification
This one could bite you on upgrade if you’re using SSH tunnels. Host key verification is now on by default. The tunnel checks ~/.ssh/known_hosts (or MYSQL_SSH_KNOWN_HOSTS, or a pinned MYSQL_SSH_HOST_KEY_FINGERPRINT) before allowing the connection.
If you were running without strict host key checking, your tunnel will fail after upgrading until you either add the host key to known_hosts or explicitly opt out with MYSQL_SSH_STRICT_HOST_KEY_CHECKING=false. The opt-out exists, but it’s a MITM risk — the default is the right behavior.
In my recent series on Scoped Vector Search, we looked at the query patterns that make vector search a first-class citizen in MySQL. While the logic for those searches is now established, the infrastructure supporting them requires constant attention as the MySQL ecosystem moves toward its new release model.
Today, I’m announcing MyVector v1.26.3. This is a foundational release focused on environment compatibility and CI/CD robustness.
What’s in v1.26.3?
This release ensures that MyVector remains stable and buildable across the shifting landscape of MySQL Innovation and LTS releases.
MySQL 8.4 & 9.6 Compatibility: We’ve updated the component sources and build logic to align with the headers and requirements for MySQL 8.4 (LTS) and the 9.6 Innovation release.
Ready for 9.7: The build system has been adapted to handle the upcoming 9.7 release, ensuring that users can transition to the next Innovation branch without delay.
Modernized Release Workflow: We’ve bumped our GitHub Actions (softprops/action-gh-release) from v1 to v2. While invisible to the user, this ensures our release pipeline remains secure and compatible with the latest GitHub runner environments.
Think of v1.26.3 as the “maintenance and readiness” layer that ensures the high-performance HNSW search you rely on continues to compile and run perfectly on the newest versions of MySQL.
Looking Ahead: The Architecture Pivot (PR #76)
While v1.26.3 keeps us current, the real excitement is happening in the lab.
Unlike the compatibility fixes in today’s release, PR #76 is a structural overhaul. We are re-engineering how the plugin interacts with the MySQL core. This shift is designed to move MyVector closer to a full Component Architecture, which will eventually offer better lifecycle management and even deeper integration with MySQL’s internal services.
This is a significant pivot in how MyVector is built, and it will set the stage for the next generation of vector performance and observability.
Summary
v1.26.3 is the stable, verified update you need for today’s MySQL 8.4/9.6 environments and tomorrow’s 9.7 upgrade. Meanwhile, work continues on the architectural evolution that will define the future of the project.
From Concepts to Production: Real-World Patterns, Query Plans, and What’s Next
In Part I, we introduced scoped vector search in MySQL using the MyVector plugin, focusing on how semantic similarity and SQL filtering work together.
In Part II, we explored schema design, embedding strategies, HNSW indexing, hybrid queries, and tuning — and closed with a promise to show real-world usage and execution behavior.
This final part completes the series.
Semantic Search with Explicit Scope
In real systems, semantic search is almost never global. Results must be filtered by tenant, user, or domain before ranking by similarity.
SELECT id, title
FROM knowledge_base
WHERE tenant_id = 42
ORDER BY
myvector_distance(embedding, ?, 'COSINE')
LIMIT 10;
This follows the same pattern introduced earlier in the series:
SQL predicates define scope
Vector distance defines relevance
MySQL remains in control of execution
Real-Time Document Recall (Chunk-Based Retrieval)
Document-level embeddings are often too coarse. Most AI workflows retrieve chunks.
SELECT chunk_text
FROM document_chunks
WHERE document_id = ?
ORDER BY
myvector_distance(chunk_embedding, ?, 'L2')
LIMIT 6;
This query pattern is commonly used for:
Knowledge-base lookups
Assistant context retrieval
Pre-RAG recall stages
Chat Message Memory and Re-Ranking
Chronological chat history is rarely useful on its own. Semantic re-ranking allows systems to recall relevant prior messages.
SELECT message
FROM chat_history
WHERE session_id = ?
ORDER BY
myvector_distance(message_embedding, ?, 'COSINE')
LIMIT 8;
The result set can be fed directly into an LLM prompt as conversational memory.
Using MyVector in RAG Pipelines
MyVector integrates naturally into Retrieval-Augmented Generation workflows by acting as the retrieval layer.
SELECT id, content
FROM documents
WHERE MYVECTOR_IS_ANN(
'mydb.documents.embedding',
'id',
?
)
LIMIT 12;
At this point:
Embeddings are generated externally
Retrieval happens inside MySQL
Generation happens downstream
No additional vector database is required.
Query Execution and Fallback Behavior
ANN Execution Path (HNSW Enabled)
Once an HNSW index is created and loaded, MySQL uses the ANN execution path provided by the plugin. Candidate IDs are retrieved first, followed by row lookups.
This behavior is visible via EXPLAIN.
Brute-Force Fallback (No HNSW Index)
When no ANN index is available, MyVector falls back to deterministic KNN evaluation.
SELECT id
FROM documents
ORDER BY
myvector_distance(embedding, ?, 'L2')
LIMIT 20;
This results in a full scan and sort — slower, but correct and predictable.
Understanding this fallback is critical for production sizing and diagnostics.
Project Update: MyVector v1.26.1
The project continues to move quickly.
MyVector v1.26.1 is now available, introducing enhanced Docker support for:
I’m grateful to all my professional and personal networks for this year. It has been full of tears, sweat, and blood all over my face once again. Let’s not worry about that. I want to start with a big Thank You to all of you who made this year possible.
If I look back at what stood out in 2025, just before we hit 2026.
Oracle ACE Pro
I was thrilled to be nominated to the Oracle ACE Program as an ACE Pro in April. This recognition opened doors to launch a technical blog series on vector search and AI integration with MySQL.
Project Antalya at Altinity, Inc.
We announced native Iceberg catalog and Parquet support on S3 for ClickHouse. This pushes the boundaries of what’s possible with open lakehouse analytics.
MySQL MCP Server
Introduced a lightweight, secure MySQL MCP server bridging relational databases and LLMs. Practical AI integration starts with safety and observability.
FOSDEM & MySQL’s 30th Birthday
I have one of my busiest agendas in ten years. It includes the MySQL Devroom Committee, a talk, and an O’Reilly book signing for #mysqlcookbook4e. Additionally, there are 6 talks from Altinity.
O’Reilly Recognition
After 50+ hours of flights for conferences, I came home to O’Reilly’s all-time recognition for the MySQL Cookbook. It was a moment I won’t forget.
Sailing While Working
Once again, months at sea with salt, humidity, and wind were challenging. We handled tickets, RCAs, and meetings. We even recorded a podcast on ferry maneuvering. Born to sail, forced to work, making it work anyway.
I am immensely grateful to the #MySQL, #ClickHouse, and #opensource communities. Thank you to my co-authors Sveta Smirnova and Ibrar Ahmed. I also thank my nominator, Vinicius Grippa. I appreciate the Altinity team and every conference organizer who gave me a stage this year.
Recognition is an invitation to contribute more, not a finish line. Looking forward to more open-source collaboration in 2026.
If you’re passionate about open-source databases, MySQL, ClickHouse, or AI integration, or just want to connect, reach out.
A lightweight, secure, and extensible MCP (Model Context Protocol) server for MySQL designed to bridge the gap between relational databases and large language models (LLMs).
I’m releasing a new open-source project: mysql-mcp-server, a lightweight server that connects MySQL to AI tools via the Model Context Protocol (MCP). It’s designed to make MySQL safely accessible to language models, structured, read-only, and fully auditable.
This project started out of a practical need: as LLMs become part of everyday development workflows, there’s growing interest in using them to explore database schemas, write queries, or inspect real data. But exposing production databases directly to AI tools is a risk, especially without guardrails.
mysql-mcp-server offers a simple, secure solution. It provides a minimal but powerful MCP server that speaks directly to MySQL, while enforcing safety, observability, and structure.
What it does
mysql-mcp-server allows tools that speak MC, such as Claude Desktop, to interact with MySQL in a controlled, read-only environment. It currently supports:
Listing databases, tables, and columns
Describing table schemas
Running parameterized SELECT queries with row limits
Running as either a local MCP-compatible binary or a remote REST API server
By default, it rejects any unsafe operations such as INSERT, UPDATE, or DROP. The goal is to make the server safe enough to be used locally or in shared environments without unintended side effects.
Why this matters
As more developers, analysts, and teams adopt LLMs for querying and documentation, there’s a gap between conversational interfaces and real database systems. Model Context Protocol helps bridge that gap by defining a set of safe, predictable tools that LLMs can use.
mysql-mcp-server brings that model to MySQL in a way that respects production safety while enabling exploration, inspection, and prototyping. It’s helpful in local development, devops workflows, support diagnostics, and even hybrid RAG scenarios when paired with a vector index.
Getting started
You can run it with Docker:
docker run -e MYSQL_DSN='user:pass@tcp(mysql-host:3306)/' \
-p 7788:7788 ghcr.io/askdba/mysql-mcp-server:latest
In Part 1, we introduced the MyVector plugin — a native extension that brings vector embeddings and HNSW-based approximate nearest neighbor (ANN) search into MySQL. We covered how MyVector supports scoped queries (e.g., WHERE user_id = X) to ensure that semantic search remains relevant, performant, and secure in real-world multi-tenant applications.
Now in Part 2, we move from concept to implementation:
How to store and index embeddings
How to design embedding workflows
How hybrid (vector + keyword) search works
How HNSW compares to brute-force search
How to tune for performance at scale
1. Schema Design for Vector Search
The first step is designing tables that support both structured and semantic data.
A typical schema looks like:
CREATE TABLE documents (
id BIGINT PRIMARY KEY,
user_id INT NOT NULL,
title TEXT,
body TEXT,
embedding VECTOR(384),
INDEX(embedding) VECTOR
);
Design tips:
Use VECTOR(n) to store dense embeddings (e.g., 384-dim for MiniLM).
Always combine vector queries with SQL filtering (WHERE user_id = …, category = …) to scope the search space.
Use TEXT or JSON fields for hybrid or metadata-driven filtering.
Consider separating raw text from embedding storage for cleaner pipelines.
2. Embedding Pipelines: Where and When to Embed
MyVector doesn’t generate embeddings — it stores and indexes them. You’ll need to decide how embeddings are generated and updated:
a. Offline (batch) embedding
Run scheduled jobs (e.g., nightly) to embed new rows.
Suitable for static content (documents, articles).
Can be run using Python + HuggingFace, OpenAI, etc.
# Python example
from sentence_transformers import SentenceTransformer
model = SentenceTransformer("all-MiniLM-L6-v2")
vectors = model.encode(["Your text goes here"])
b. Write-time embedding
Embed text when inserted via your application.
Ensures embeddings are available immediately.
Good for chat apps, support tickets, and notes.
c. Query-time embedding
Used for user search input only.
Transforms search terms into vectors (not stored).
Passed into queries like:
ORDER BY L2_DISTANCE(embedding, '[query_vector]') ASC
3. Hybrid Search: Combine Text and Semantics
Most real-world search stacks benefit from combining keyword and vector search. MyVector enables this inside a single query:
SELECT id, title
FROM documents
WHERE MATCH(title, body) AGAINST('project deadline')
AND user_id = 42
ORDER BY L2_DISTANCE(embedding, EMBED('deadline next week')) ASC
LIMIT 5;
This lets you:
Narrow results using lexical filters
Re-rank them semantically
All in MySQL — no sync to external vector DBs
This hybrid model is ideal for support systems, chatbots, documentation search, and QA systems.
4. Brute-Force vs. HNSW Indexing in MyVector
When it comes to similarity search, how you search impacts how fast you scale.
Brute-force search
Compares the query against every row
Guarantees exact results (100% recall)
Simple but slow for >10K rows
SELECT id
FROM documents
ORDER BY COSINE_DISTANCE(embedding, '[query_vector]') ASC
LIMIT 5;
HNSW: Hierarchical Navigable Small World
Graph-based ANN algorithm used by MyVector
Fast and memory-efficient
High recall (~90–99%) with tunable parameters (ef_search, M)
CREATE INDEX idx_vec ON documents(embedding) VECTOR
COMMENT='{"HNSW_M": 32, "HNSW_EF_CONSTRUCTION": 200}';
Comparison
Feature
Brute Force
HNSW (MyVector)
Recall
✅ 100%
🔁 ~90–99%
Latency (1M rows)
❌ 100–800ms+
✅ ~5–20ms
Indexing
❌ None
✅ Required
Filtering Support
✅ Yes
✅ Yes
Ideal Use Case
Small datasets
Production search
5. Scoped Search as a Security Boundary
Because MyVector supports native SQL filtering, you can enforce access boundaries without separate vector security layers.
Patterns:
WHERE user_id = ? → personal search
WHERE org_id = ? → tenant isolation
Use views or stored procedures to enforce access policies
You don’t need to bolt access control onto your search engine — MySQL already knows your users.
6. HNSW Tuning for Performance
MyVector lets you tune index behavior at build or runtime:
Param
Purpose
Effect
M
Graph connectivity
Higher = more accuracy + RAM
ef_search
Traversal breadth during queries
Higher = better recall, more latency
ef_construction
Index quality at build time
Affects accuracy and build cost
Example:
ALTER INDEX idx_vec SET HNSW_M = 32, HNSW_EF_SEARCH = 100;
You can also control ef_search per session or per query soon (planned feature).
TL;DR: Production Patterns with MyVector
Use VECTOR(n) columns and HNSW indexing for fast ANN search
Embed externally using HuggingFace, OpenAI, Cohere, etc.
Combine text filtering + vector ranking for hybrid search
Use SQL filtering to scope vector search for performance and privacy
Tune ef_search and M to control latency vs. accuracy
Coming Up in Part 3
In Part 3, we’ll explore real-world implementations:
Semantic search
Real-time document recall
Chat message memory + re-ranking
Integrating MyVector into RAG and AI workflows
We’ll also show query plans and explain fallbacks when HNSW is disabled or brute-force is needed.
Semantic Search with SQL Simplicity and Operational Control
Introduction
Vector search is redefining how we work with unstructured and semantic data. Until recently, integrating it into traditional relational databases like MySQL required external services, extra infrastructure, or awkward workarounds. That changes with the MyVector plugin — a native vector indexing and search extension purpose-built for MySQL.
Whether you’re enhancing search for user-generated content, improving recommendation systems, or building AI-driven assistants, MyVector makes it possible to store, index, and search vector embeddings directly inside MySQL — with full support for SQL syntax, indexing, and filtering.
What Is MyVector?
The MyVector plugin adds native support for vector data types and approximate nearest neighbor (ANN) indexes in MySQL. It allows you to:
Define VECTOR(n) columns to store dense embeddings (e.g., 384-dim from BERT)
Index them using INDEX(column) VECTOR, which builds an HNSW-based structure
Run fast semantic queries using distance functions like L2_DISTANCE, COSINE_DISTANCE, and INNER_PRODUCT
Use full SQL syntax to filter, join, and paginate vector results alongside traditional columns
By leveraging HNSW, MyVector delivers millisecond-level ANN queries even with millions of rows — all from within MySQL.
Most importantly, it integrates directly into your existing MySQL setup—there is no new stack, no sync jobs, and no third-party dependencies.
Scoped Vector Search: The Real-World Requirement
In most production applications, you rarely want to search across all data. You need to scope vector comparisons to a subset — a single user’s data, a tenant’s records, or a relevant tag.
MyVector makes this easy by combining vector operations with standard SQL filters.
Under the Hood: HNSW and Query Performance
MyVector uses the HNSW algorithm for vector indexing. HNSW constructs a multi-layered proximity graph that enables extremely fast approximate nearest neighbor search with high recall. Key properties:
Logarithmic traversal through layers reduces search time
Dynamic index support: you can insert/update/delete vectors and reindex as needed
Configurable parameters like M and ef_search allow tuning for performance vs. accuracy
Under the Hood: HNSW and Query Performance
MyVector uses the HNSW algorithm for vector indexing. HNSW constructs a multi-layered proximity graph that enables extremely fast approximate nearest neighbor search with high recall. Key properties:
Fast ANN queries without external services
Scoped filtering before vector comparison
Logarithmic traversal through layers reduces search time
Dynamic index support: you can insert/update/delete vectors and reindex as needed
Configurable parameters like M and ef_search allow tuning for performance vs. accuracy
What’s Next
This post introduces the foundational concept of scoped vector search using MyVector and HNSW. In Part II, we’ll walk through practical schema design patterns, embedding workflows, and hybrid search strategies that combine traditional full-text matching with deep semantic understanding — using nothing but SQL.
After the most memorable MySQL community event, #MySQLBelgianDays2024, and earning legendary recognition from the MySQL Community team, I have decided to share some thoughts about the importance of a community.
Previously in life
As a former enterprise DBA, I have been part of other communities strictly focused on monetary and entitlement of accomplishments. I had a chance to work on world-leading enterprises and had ability access to the most advanced technologies for both software and hardware. This journey was fun, fruitful, and rewarding for me.
In the latter half of my career, I entered the open-source community of MySQL by shifting my prior decade and a half of experience into it.
Entry to the open-source community
When I entered this community full-time, there were several controversial discussions and assumptions about Oracle’s acquisition of MySQL, the separation of MariaDB, etc. While some of those claims had some reality, most turned out to be baseless without knowing the intentions and future.
The importance of Percona Live events and the Oracle MySQL team’s contributions to this community, which several other open-source contributors surrounded, was my entry point. There was a significant influence from hyper-scalers, known as initially social media companies, followed by SAAS and cloud vendors.
I have watched, followed, and strictly learned from community leaders, including influencers like Peter Zaitsev. Although open-source communities feel and look like closed-circuit groups of geeks having fun, they are very open to newcomers. But remember, communities accept contributors, not watchers. What I mean by contributors is not just coming to a company-paid trip to the event once in a blue moon. Even if you attend an event as a visitor, you can still help by promoting and getting the word out through social media and other networks.
Where to start?
One can share ideas, code tools, and software and become a speaker. If you aren’t the type of person who can speak and present, you can help others by providing content and ideas and having them review them. Let me help you get there and recognitions will follow.
How do I start helping and becoming a part of the community?
Create a public repository of the tools and code you spend time on.
Start writing blogs about your experiences and sharing content.
Become a speaker or co-speaker with the same or similar subject.
Conduct webinars and post-speaking events for those who were not able to attend. Include feedback and corrections to your talk.
Create training content on recorded videos and training sites.
Coordinate or help with local meetups.
Help sponsoring events.
Encourage to send co-workers to events.
Introduce newcomers to community veterans.
Author or co-author books and booklets.
Act as an event committee member.
Help to answer questions via GitHub issues or Slack channels.
Always spread the word through social channels.
If you still can’t do any of those, help marketing colleagues carry boxes of swag and give away materials, and set up and clean up booths for the events. You can always help sales and pre-sales folks by connecting your network.
I have to credit Laine Campbell for introducing me to and allowing me to meet the most influential leaders of the MySQL community.
Many thanks to Peter Zaitsev for all the help, support, and openness in accepting me into the MySQL community.
I would also like to thank the past, current, and future MySQL Community team for their hard work. The rest of the list is too long to mention here, but they know who they are.
Congratulations to all previous MySQL Rockstars and 2023 winners.