I was able to get the MySQL MCP Server up and running and it was time to try it first time against a sample data set outside of its test suite.
Let’s start with Stack Overflow and the value of its data for modern LLMs and AI systems. As most of you already know, the questions in forums has significantly dropped since the launch of OpenAI, aka ChatGPT
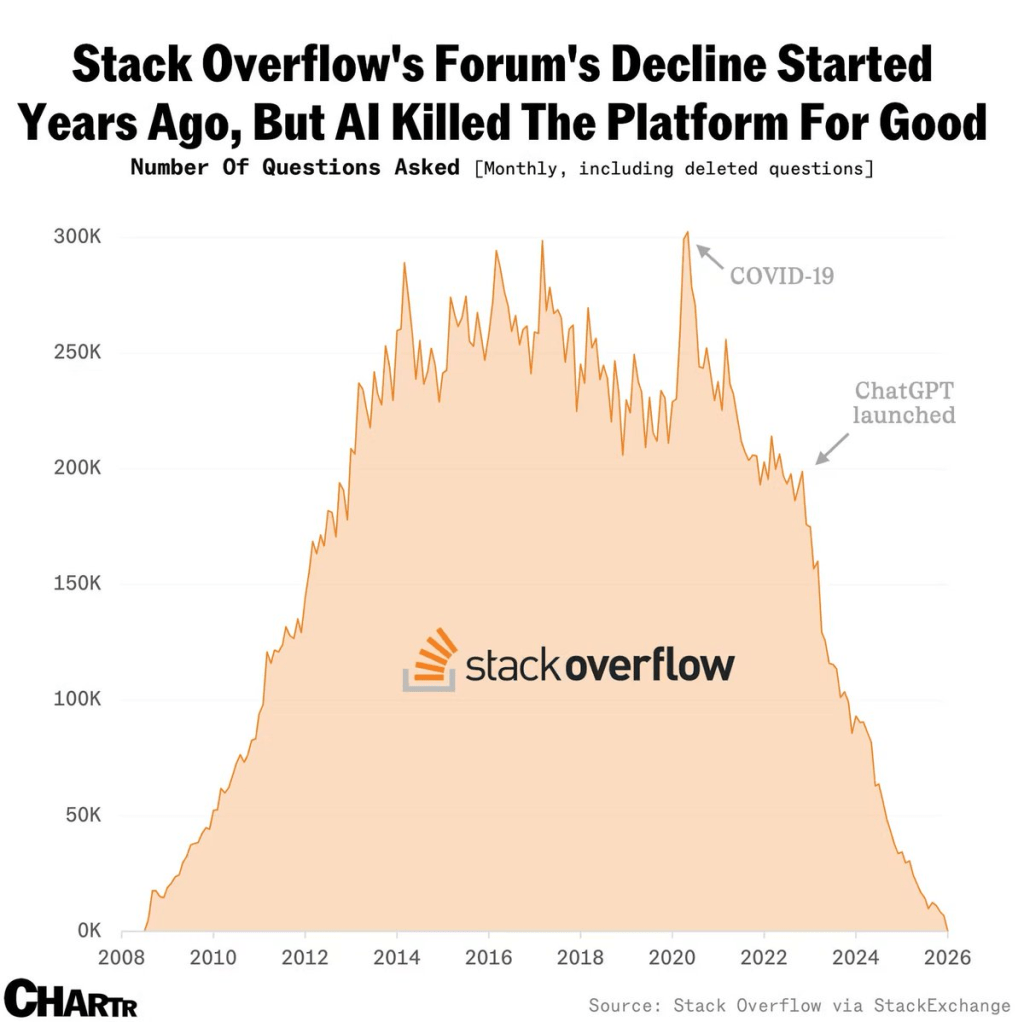
Source : https://x.com/alojoh/status/2009366134513127462
This is probably true for traditional search engines like Google, although they’re already adopting built-in AI solutions. Other sources, such as Reddit, also provided valuable, quick, and easy information to the masses.
I wanted to spin a subset of StackExchange questions. These are loaded into a local MySQL server. I intended to put the MCP server to a test to find out what’s going on.
Results aren’t only interesting but also very intriguing. The reason is the questions at these forums and their answers. If these questions and answers don’t exist, how will LLMs train themselves to give precise answers? They may otherwise rely on other outdated sources and start hallucinating.
So first thing we spin up the lastes version of the mysql-mcp-server and configure it to work with Claude desktop per the instructions in the documentation. Basically, get the data sample dataset from the StackExchange data dump site. You can ask Cursor, Gemini, or Claude for help. They can set up this data sample in your local MySQL database server. Here’s the github repository for this data set as well.
My prompt: Explore Stack Exchange database
🚁 Stack Exchange: Drones & Model Aircraft – Complete Analysis
📊 Community Overview
Site: Drones and Model Aircraft Stack Exchange
Period: April 2020 – March 2024 (4 years)
Status: 🚨 Declining but quality community
| Metric | Value |
|---|---|
| Total Questions | 908 |
| Total Answers | 1,277 |
| Total Users | 5,251 |
| Total Votes | 9,983 |
| Avg Answers/Question | 1.41 |
| Acceptance Rate | 49.45% |
| Avg Question Views | 757 |
I will not copy and paste the rest of the conversation. It’s a big, long one. However, the results are amazing on the subject of Drones.
As a drone pilot for almost a decade, the following questions are seriously intriguing.
🔥 Most Viral Questions (5K+ Views)
| Title | Views | Score | Answers |
|---|---|---|---|
| At what current should I charge a LiPo battery? | 24,278 | 9 | 4 |
| Why do brushless motors have 3 wires? | 17,834 | 8 | 2 |
| What do ESC beeps mean? | 16,444 | 5 | 2 |
| How come DJI Fly App is NOT in Play Store? | 15,826 | 12 | 4 |
| How to configure servo in Betaflight? | 12,052 | 5 | 2 |
Prompt: Why do multirotors usually have four propellers?
✅ ACCEPTED ANSWER (27 upvotes) – by Kenn Sebesta
TL;DR: Four is the mathematical minimum for simple, robust control
The Physics: 4 Degrees of Freedom
For hovering aircraft, we need to control 4 degrees of freedom (DoF):
- Roll (tilt left/right)
- Pitch (tilt forward/backward)
- Yaw (rotate clockwise/counterclockwise)
- Thrust (up/down)
(We can control horizontal movement (x-y) by combining roll/pitch with thrust)
These are some samples. If you run it yourself, there are amazing insights into the data set. Not only that, but you can question the results, trends, and answers.
Going back to MySQL and like any other database out of the box query optimization was terribly wrong. We dug in a bit further. We discovered that most of the queries it ran for the above results were inefficient.
1. Row Count Query – 100x Faster ⚡
Problem: 9 separate full table scans
Solution: Use information_schema.TABLES metadata
Speedup: 2000ms → 20ms
2. Top Users with Posts – 50x Faster ⚡⚡
Problem: Joins ALL posts for ALL users before filtering
Solution: Filter to top 15 users FIRST, then join
Speedup: 800ms → 15ms
✅ Tested successfully – Works perfectly!
3. Monthly Activity – 10x Faster ⚡
Problem: YEAR() and MONTH() functions prevent index usage
Solution: Use DATE_FORMAT() and index-friendly WHERE
Speedup: 500ms → 50ms
4. Vote Percentages – 10x Faster ⚡
Problem: Subquery recalculates total count for each group
Solution: Calculate once with CTE or window function
Speedup: 400ms → 40ms
5. Answer Distribution – 3x Faster ⚡
Problem: CASE expression in GROUP BY
Solution: Group by integer bucket IDs, then label
Speedup: 300ms → 100ms
This led me to create an optimization guide for the Claude agent.
In conclusion, the MCP servers are great resources to explore data sets. With some experimentation and guidance, they can reveal highly valuable analytics use cases. These include marketing and sales data that would normally take too much time and material to cover.
Next up is token usage. If you are also wondering, “Where have all my tokens gone using these AI tools?” I have some thoughts on that topic, too.




